OpenAI just dropped ChatGPT Images 2.0, and it marks the beginning of the reasoning era for AI art. Here is everything you need to know about the transition from DALL-E 3 and what these new agentic capabilities actually mean for your workflow.
ChatGPT Images 2.0 (GPT-Image-2) is OpenAI's latest image generation model that replaces DALL-E 3. It introduces an agentic architecture that reasons through layouts, searches the web for accuracy, and renders complex text in multiple languages. It represents a shift from simple image generation to a visual system capable of production-ready assets.
What is ChatGPT Images 2.0?
ChatGPT Images 2.0, also known as GPT-Image-2, is a fundamental shift in how OpenAI approaches visual media. For years, image generators operated as black boxes. You would provide a prompt, and the model would attempt to reconstruct an image from noise. This often led to issues with spatial reasoning, malformed text, and a lack of physical awareness.
With this new release, OpenAI is moving away from simple generation and toward agentic visual systems. This means the model does not just draw. It plans. By integrating OpenAI’s O-series reasoning capabilities, the system researches and reasons through the structure of an image before the first pixel is rendered.
At its core, GPT-Image-2 is designed to close the intent gap. When you ask for a complex infographic or a detailed technical diagram, the model understands the logical layout required to make that information readable. This approach is similar to how we built eesel AI. Just as GPT-Image-2 reasons through visual layouts, our AI teammate reasons through your company's data to provide autonomous support and internal knowledge.
The model also features a significantly updated knowledge base. While previous versions often struggled with modern context, the knowledge cutoff for GPT-Image-2 is December 2025. This allows it to generate images involving recent events or newer technologies with much higher accuracy.
The 4 key upgrades: Agentic thinking and performance
The transition from DALL-E 3 to GPT-Image-2 is defined by four primary pillars. These upgrades move the model from a creative toy to a professional-grade tool for marketing, design, and education.
1. Agentic "thinking mode"
The headline feature of ChatGPT Images 2.0 is its ability to think. When you select a thinking model within ChatGPT, the system performs several background steps before generating. It researches the context of your prompt, plans the composition, and double-checks its own logic.
This agentic approach allows for a level of complexity previously impossible. For example, the model can now synthesize uploaded documents such as PDFs or PowerPoint files into visual explainers. If you upload a strategy deck, the model can identify your logos, understand your data, and produce a professional poster that maintains the original file's stylistic constraints.
Perhaps most importantly for creators, GPT-Image-2 can generate up to 8 distinct images from a single prompt while maintaining character and object continuity. This solves the long-standing storyboard problem, allowing for the creation of consistent manga sequences or branded social media sets. For more on how this type of logic is reshaping work, you can read our deep dive into agentic AI.
2. 4x faster generation
While the thinking mode takes extra time to reason through complex tasks, the underlying base model is significantly more efficient. OpenAI has revamped the architecture from scratch to improve throughput.
The performance gains are measurable. According to OpenAI, GPT-Image-2 achieves 4x greater throughput efficiency per GPU compared to legacy models. This means that for standard generation tasks, you are seeing your vision come to life much faster without a loss in quality.
3. Photorealism and physical awareness
Historical AI models often struggled with physics. Objects would overlap in ways that defied gravity, or lighting would feel inconsistent across a scene. GPT-Image-2 addresses this by incorporating a deeper understanding of lighting and material properties.
The persistent warm color cast found in previous iterations has been removed. The result is neutral, accurate color rendering that feels more like professional photography than an AI generation. Additionally, the technical specifications now support up to 2K resolution in the ChatGPT interface and up to 4K resolution (3840px edge) in the API beta.
4. Multilingual text rendering
Text has always been the Achilles' heel of AI image models. ChatGPT Images 2.0 marks a step change in this department. It can produce readable typography even in dense compositions like menus or scientific diagrams.
OpenAI has also focused on ending the Western bias in AI imagery. The model now supports high-fidelity text rendering in Japanese, Korean, Chinese, Hindi, and Bengali. It doesn't just translate text. It renders it natively, ensuring that the characters and spacing feel authentic to the language.
GPT-Image-2 vs. DALL-E 3: What’s the difference?
Comparing GPT-Image-2 to DALL-E 3 is like comparing a generalist researcher to a simple artist. DALL-E 3 was excellent at creative interpretation, but it lacked the reasoning necessary for high-stakes professional work.
| Feature | DALL-E 3 | ChatGPT Images 2.0 (GPT-Image-2) |
|---|---|---|
| Architecture | Diffusion-based | Agentic Reasoning System |
| Text Quality | Often malformed or misspelled | Near-perfect in multiple languages |
| Logic & Planning | Direct prompt-to-image | Researches and plans before rendering |
| Consistency | Low (requires manual stitching) | High (up to 8 images with continuity) |
| Max Resolution | 1024 x 1024 | 2K (ChatGPT) / 4K (API Beta) |
| Web Search | No | Yes (real-time visual grounding) |
The introduction of web search for visual grounding is a major differentiator. If you ask for an image of a specific current event or a technical artifact, the model can search the web to ensure the visual details are accurate. This moves AI generation from imagination into the realm of factual representation.
This shift in capability mirrors the competitive landscape we see in the broader AI market. For a look at how OpenAI stacks up against other giants, check out our comparison of Gemini vs ChatGPT.
Access tiers: Free vs. paid tiers and API access
OpenAI has structured access to ChatGPT Images 2.0 to balance casual use with professional needs. While everyone gets a taste of the new model, the most advanced features are gated.
- Free users: Have access to the base model for standard image generation tasks.
- Plus and Pro users: Can access thinking capabilities, which include tool use, web search, and multi-image generation with continuity.
- API Developers: Can integrate gpt-image-2, which supports flexible aspect ratios from 3:1 to 1:3 and custom resolutions up to 8.2M pixels.
The API pricing has been updated to reflect the new model's capabilities. OpenAI has actually shaved $2 off the output side compared to previous flagship tiers.
For developers, the API for GPT-Image-2 offers high-quality parameters and quality-based pricing. This allows you to choose between lower fidelity for speed or high fidelity for production-ready assets.
GPT-Image-1.5 and the May 2026 developer roadmap
With the launch of version 2.0, OpenAI has confirmed that it is deprecating GPT-Image-1.5 as the default model. However, 1.5 is not disappearing entirely.
For developers who built specialized workflows around the interim model, the official GPT-Image-1.5 API will open for legacy support in May 2026. This ensures that enterprise applications relying on specific lighting or stylistic outputs from that version can continue to function while they transition to the newer reasoning-based stack.
The developer roadmap also includes expanded support for image editing with mask support. This endpoint allows for precise inpainting and outpainting, enabling use cases like product background swaps or packaging visualization.
Publishing visual content at scale with eesel AI
As models like ChatGPT Images 2.0 (GPT-Image-2) make it easier to generate high-quality visuals, the challenge for content teams shifts from creation to orchestration. Generating a great image is one thing. Publishing 50 well-researched, visually rich blog posts a month is another.
That is why we built the eesel AI blog writer. Our AI teammate doesn't just write. It acts as a full-stack content engine. We designed it to learn your specific brand voice and your actual company data from tools like Confluence or Google Docs.
When you use our AI blog generator, you get more than just text. We handle the deep research, SEO optimization, and the integration of assets. This allows your team to focus on strategy and editing while we handle the heavy lifting.
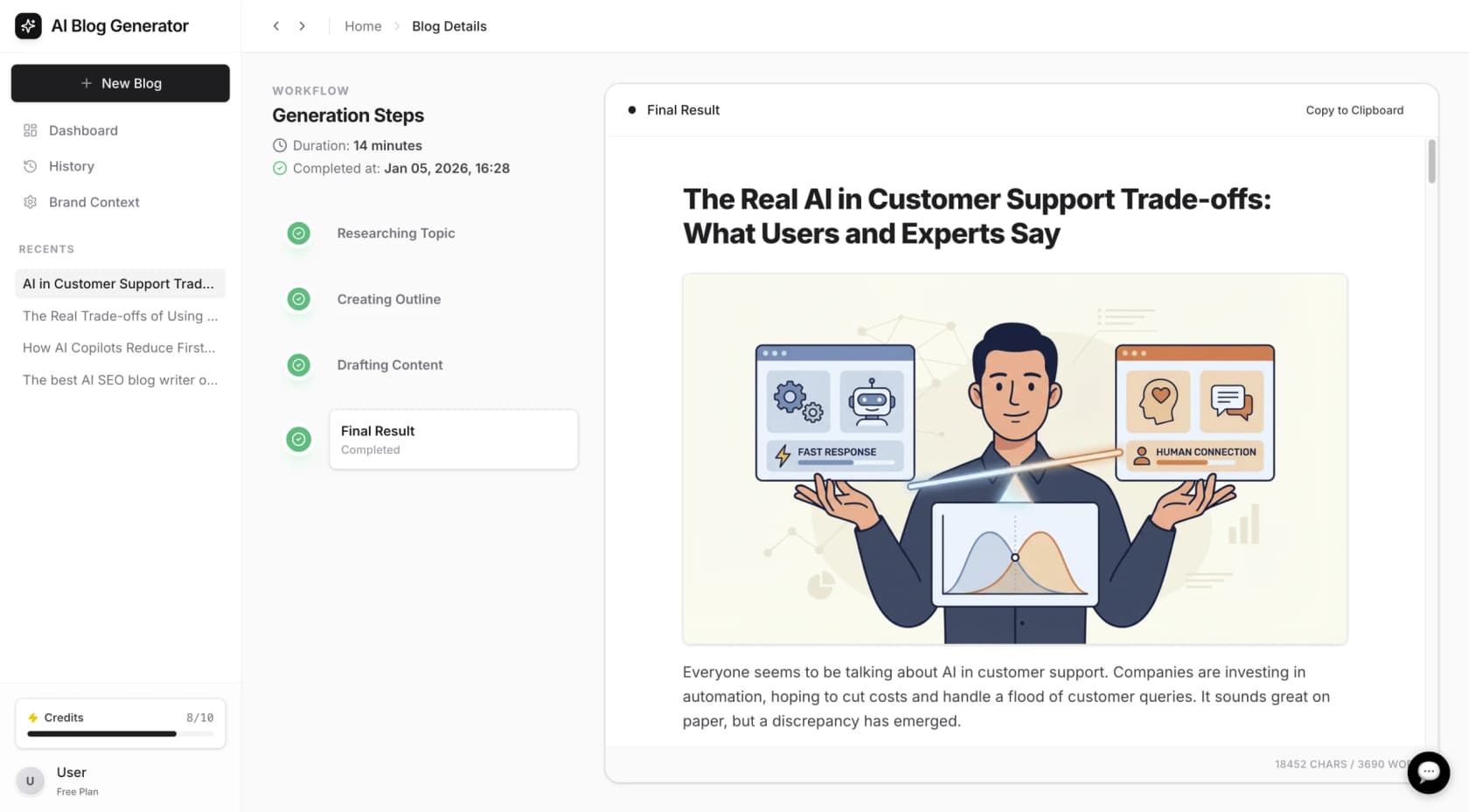
The future of professional creative work isn't just about better prompts. It's about agentic systems that can think through complex problems. Whether you are using GPT-Image-2 for a storyboard or hiring an eesel AI agent for your helpdesk, the goal is the same: leveling up your team's autonomy.
Bottom line? The era of AI as a simple tool is over. The era of the AI teammate has begun. You can see how we compare to other options in our AI blog writer comparison or explore our pricing to get started.
Frequently Asked Questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.

