What Qwen is (and why it's different)
Qwen (通义千问) is Alibaba Cloud's large language model family - a sprawling catalogue of more than 145 model IDs spanning text, vision, audio, code, translation, video generation, and embeddings, all accessible under one API key via Qwen Cloud / Alibaba Cloud Model Studio.
Three things make it unusual in the LLM market:
- Open-weight models alongside proprietary ones. The entire Qwen3 series (0.6B through 235B-A22B) is Apache 2.0 licensed and available on Hugging Face. You can run the same model you'd pay the API for, locally, for free.
- MoE architecture dominates the mid-tier. Most of Qwen's competitive pricing comes from Mixture-of-Experts design - the 235B-A22B model activates only 22B parameters per token, making its inference cost similar to a 22B dense model despite 235B total scale.
- Volume at a scale few providers match. Qwen3.6-Plus was the first model on OpenRouter to process 1T+ tokens in a single day - a signal of how much developer adoption has shifted toward the Qwen family.
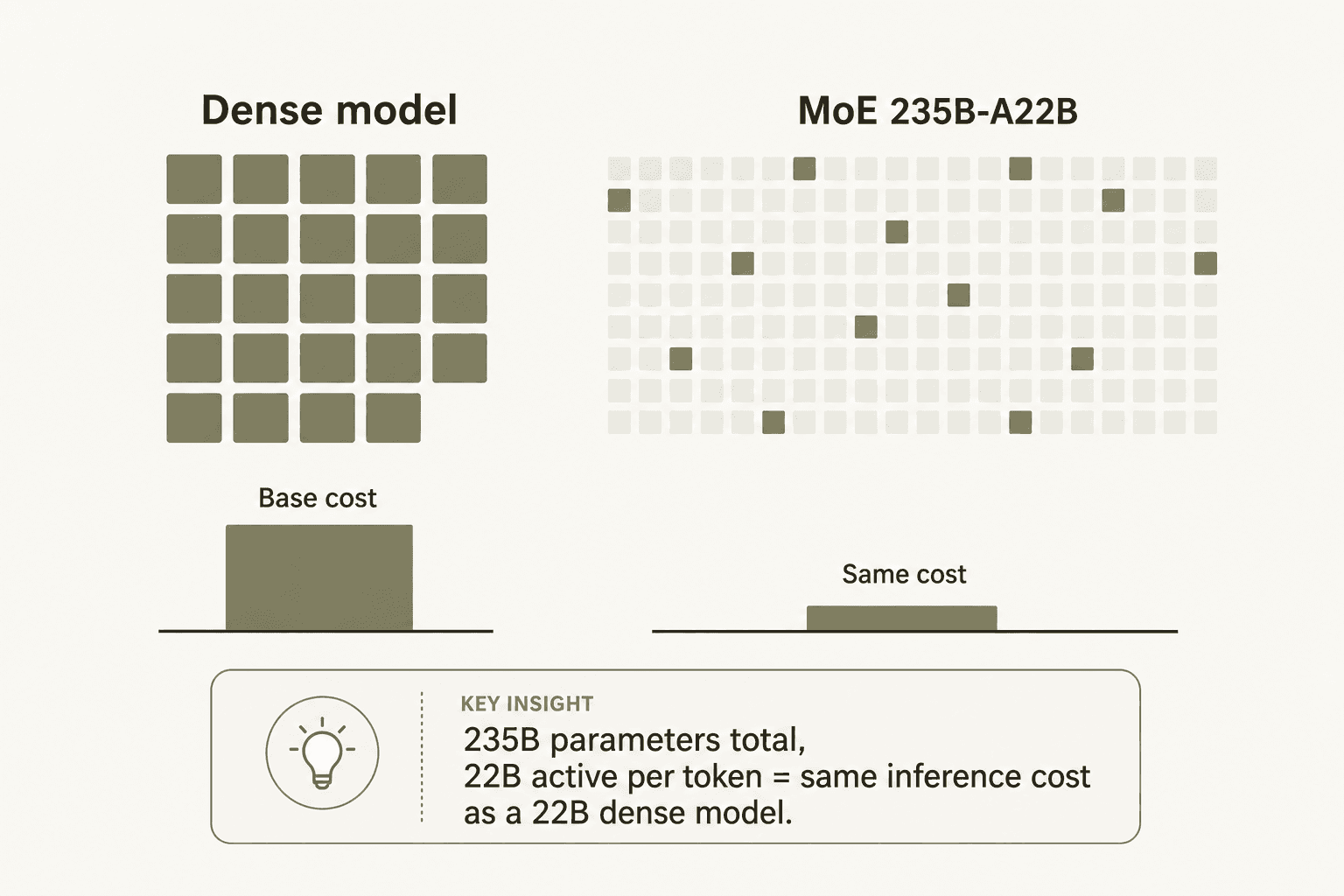
"The MoE Design: Most MoE models feel like bolt-ons. Qwen 3.5's sparse activation is native - only 4.3% of parameters fire per token. That's how you get trillion-parameter-class performance without trillion-parameter inference costs. The 0.8 RMB/million tokens pricing isn't subsidized; it's structurally earned."
Full Qwen API pricing table (2026)
All prices in USD, pay-as-you-go on the international endpoint (Alibaba Cloud Model Studio, ap-southeast-1). Prices sourced from Qwen Cloud model detail pages and PricePerToken.com (checked June 3, 2026).
Text generation models
| Model | Input $/1M | Output $/1M | Context | Notes |
|---|---|---|---|---|
| Qwen3.7-Max | $1.25 | $3.75 | 1M tokens | 50% promo off $2.50/$7.50 list; text-only; launched 2026-05-21 |
| Qwen3.7-Plus | $0.32–$0.96 | $1.28–$3.84 | 1M tokens | Native multimodal; tiered by context length; launched 2026-06-01 |
| Qwen3-Max | $1.20 | $6.00 | 262K tokens | Agent-optimized; cache read $0.12/1M |
| Qwen3.6-Plus | $0.50–$2.00 | $3.00–$6.00 | 1M tokens | Native multimodal; agentic coding; visual + text |
| Qwen3.6-Flash | $0.25–$1.00 | $1.50–$4.00 | 1M tokens | Cost-optimized vision-language |
| Qwen3-235B-A22B | $0.70 | $2.80 / $8.40* | 131K tokens | MoE flagship open-weight; *thinking mode |
| Qwen3-30B-A3B | $0.20 | $0.80 / $2.40* | 131K tokens | Balanced MoE; *thinking mode |
| Qwen3-8B | $0.18 | $0.70 / $2.10* | 131K tokens | Dense small; *thinking mode |
| Qwen-Max | $1.60 | $6.40 | 32K tokens | Stable production alias |
| Qwen-Plus | $0.40 | $1.20 / $4.00* | 1M tokens | Stable alias; *thinking mode |
| Qwen-Turbo | $0.05 | $0.20 / $0.50* | 131K tokens | Cheapest text tier; 5M TPM throughput; *thinking mode |
| Qwen3.5-0.8B | $0.01 | $0.05 | - | Absolute floor; micro-automation tasks |
*Thinking mode output billed at the higher rate when enable_thinking: true
Vision-language and multimodal models
| Model | Input $/1M | Output $/1M | Context |
|---|---|---|---|
| Qwen3-VL-Plus | $0.20 | $1.60 | 262K tokens |
Embedding models
| Model | Price |
|---|---|
| text-embedding-v3 / text-embedding-v4 | $0.07/1M tokens; $0.035/1M batch |
Video generation models
| Model | Price |
|---|---|
| HappyHorse-1.0 series (T2V, I2V, R2V, edit) | $0.112/second |
| Wan2.7-T2V | $0.10/second |
Pricing ranges on Qwen3.7-Plus and Qwen3.6-series reflect tiered input brackets - cost per million tokens escalates as the input length grows within a single request (not cumulative usage). The $0.32 rate applies to short inputs; $0.96 kicks in for long-context requests on Qwen3.7-Plus.
How billing actually works
Understanding the rate card is step one. Understanding how those rates combine in a real workload is where people get surprised.
Thinking mode
Several Qwen3-generation models support an optional enable_thinking: true parameter that triggers chain-of-thought reasoning before the final answer. The thinking tokens are generated internally and then billed - at rates typically 3-10x standard output. On Qwen-Plus, for example, standard output costs $1.20/1M but thinking output costs $4.00/1M. On Qwen3-235B-A22B, thinking output jumps from $2.80 to $8.40/1M.
For most production workloads - classification, summarization, structured extraction - thinking mode is overkill. Turn it on for reasoning-heavy tasks only (complex code review, multi-step planning, math), and budget accordingly when you do.
Prompt caching
Implicit prompt caching is automatic on most Qwen models: repeated context prefixes get cached, and cache hits are billed at roughly 20% of the standard input rate. For Qwen-Plus, that's $0.08/1M instead of $0.40/1M on cached portions.
There's also explicit cache management available on Qwen3-Max and Qwen-Plus:
- Cache creation: ~$0.50/1M (125% of input rate)
- Cache read: ~$0.04/1M (10% of input rate)
The catch raised consistently in the community: Qwen's caching hits less reliably than competitors. One Reddit user ran the same code review task across four AI CLIs and found Qwen burned 23% of their $30 monthly quota on a single task - the same task consumed under 1% of comparable $100 Claude and $100 OpenAI plans. The explicit diagnosis: "They do not appear to cache as well as other model providers."
Batch processing
The asynchronous batch API offers roughly 50% off standard rates for non-real-time workloads. On Qwen3-Max, batch input drops from $1.20 to $0.60/1M; batch output from $6.00 to $3.00/1M. For ETL pipelines, bulk classification jobs, or overnight report generation, batch mode is the right default.
Savings plans
Alibaba Cloud offers AI Savings Plans with up to 47% cost reduction via usage commitment. There's also an AI Token Plan - fixed subscription credits across models - but community experience with this is mixed (see What you actually pay, below).
What you actually pay in practice
Sticker prices and real invoices diverge. Here are three worked examples grounded in real-world data.
Example 1: a content pipeline at 10,000 tasks/day
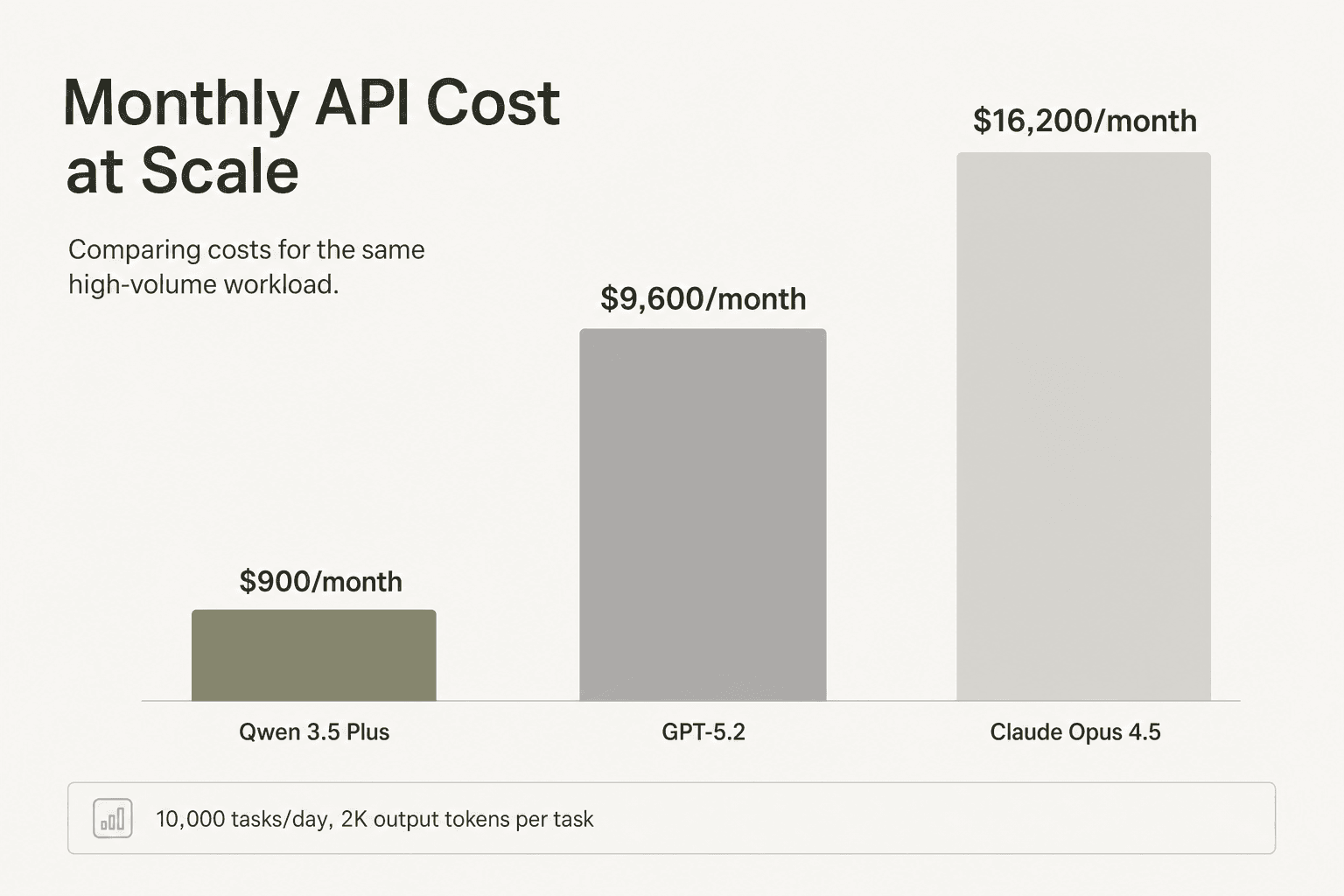
ChartGen AI benchmarked Qwen 3.5 vs GPT-5.2 vs Claude Opus 4.5 on 20 data visualization tasks, each requiring roughly 2K output tokens. The economics at 10K tasks/day:
| Model | Cost per task | Daily cost | Monthly cost |
|---|---|---|---|
| Qwen 3.5-35B-A3B | ~$0.003 | ~$30 | ~$900 |
| GPT-5.2 | ~$0.032 | ~$320 | ~$9,600 |
| Claude Opus 4.5 | ~$0.054 | ~$540 | ~$16,200 |
Qwen scored 163/200 in the benchmark vs. GPT-5.2 at 178/200 - a 9% quality gap at a 10x cost reduction.
The ChartGen team also flagged the multi-agent multiplier:
"In ChartGen AI's pipeline, a single dashboard generation invokes the model 5-8 times... At this scale, you can run 10 Qwen 3.5 agents for the price of 1 GPT-5.2 call - and use ensemble voting to exceed any single model's accuracy."
Steven Cen, ChartGen AI [Source]
Example 2: the Intelligence Index infrastructure test
Artificial Analysis ran Qwen3.6 Plus through their full Intelligence Index benchmark. Total cost:
- Qwen3.6 Plus: $483 (~100M output tokens at $0.50/$3.00)
- Claude Opus 4.6 (max effort): $4,970
That's a 10x cost difference for a 2-point intelligence score gap (Qwen3.6 Plus scored 51 vs Claude Opus 4.6 at 53 on their index). The caveat: Qwen generated noticeably more output tokens per task than peers, which inflated costs compared to a less verbose model at the same per-token rate.
Example 3: the Token Plan sticker shock
Qwen's newer subscription offering - the AI Token Plan - converts dollars to credits in ways that confused many early adopters. From a May 2026 Reddit thread:
"I signed up for the $30 plan (which offers 25,000 credits)... in just 4 hours of use [with Qwen 3.6 Plus], [I burned through] approximately 8,000 credits (out of a total of 25,000 credits in the $30 plan)."
The head-to-head comparison by user qu1etus is damning for the Token Plan specifically:
"qwen3.7-max (using qwen cli - $30 plan): used 23% of my monthly quota. gpt-5.5 xhigh (using codex cli - $100 plan): used <1% of monthly quota. opus 4.7 (using claude code - $100 plan): used <1% of monthly quota. For the cost though, I'm out. They do not appear to cache as well as other model providers and their pricing model is broken."
The raw pay-as-you-go API rate is better than the Token Plan math suggests. If you're comparing Qwen against Claude or OpenAI, stick to per-token API pricing rather than the subscription plan tiers.
Qwen pricing tiers: picking the right model
Not every workload needs the Max tier. The architecture decision usually matters more than the model generation.

Qwen-Turbo ($0.05/$0.20) - the right call for classification, routing, extraction, and any workload where you need throughput at low cost. At 5M tokens per minute rate limit, it handles aggressive batch pipelines without hitting caps. One Reddit user put it bluntly: "At seven cents per million tokens, it feels like cheating."
Qwen3-30B-A3B ($0.20/$0.80) - the balanced MoE choice. The 30B-A3B activates only 3B parameters at inference, runs at ~137 tokens/second on a single H20 GPU, and covers the vast majority of coding and reasoning tasks that don't need Max-tier capability. Community consensus on r/LocalLLaMA: the 35B-A3B MoE variant runs 15x faster than the 27B dense at a fraction of the cost - always pick the MoE if there's one at your target size.
Qwen-Plus ($0.40/$1.20) - the stable production alias with 1M context. If you need a predictable API ID that won't change between model updates, this is it. Thinking mode available at $4.00/1M output.
Qwen3.7-Plus ($0.32–$0.96/$1.28–$3.84) - the native multimodal option with 1M context and agentic coding capabilities. Good fit for pipelines that mix text, image, and tool-calling in the same call.
Qwen3-Max / Qwen3.7-Max ($1.20–$1.25 / $6.00–$3.75) - approaching frontier pricing territory. The community found that the 480B MoE Coder variant often makes more sense than Max for heavy coding at $1.50/$7.50, unless you specifically need the Max architecture's agent pipeline optimization. At the discounted $1.25 for Qwen3.7-Max, it's competitive with mid-tier GPT-5 pricing - but the discount is listed as promotional.
The free tier situation in 2026
This is the part that trips people up most.
What is free: The Qwen Studio consumer chat app - no sign-up required, no rate limits communicated, supported on iOS, Android, macOS, and web. This isn't going away. Alibaba has strong commercial incentives to keep the consumer product free.
What was free and is now gone: The developer OAuth API free tier - which allowed 1,000 (later 100) requests/day via the API - was discontinued on April 15, 2026. The Qwen Code CLI's 2,000-requests/day free coding tier was also eliminated around the same time. Community reaction was immediate:
"ngl i just subscribed to claude. I had qwen make .md files of everything so claude could just pick up from there."
u/ihateroomba, 3 upvotes
One analytically sharp Reddit comment explained the distinction well:
"It's important to distinguish between two distinct worlds that coexist at Alibaba: The 'Consumer Product' world (Qwen Studio): The app you use on your phone is a finished product. Alibaba has every interest in keeping it free... The 'Developer / API' world: This is where the policy has changed... It's a classic strategy: attract users with the free version, then charge them when it scales."
What's still available as a free trial: New Alibaba Cloud Model Studio accounts receive 70M+ tokens free across Qwen models (1M tokens per model), plus 1,650 seconds of video generation credit. Valid for 90 days, Singapore endpoint only. The US Virginia endpoint has no free quota.
The self-hosting floor price
There's a number the API pricing tables don't show: $0.00 per token, available to anyone willing to run their own inference.
All Qwen3 models (0.6B through 235B-A22B) are Apache 2.0 open-weight and available on Hugging Face. @WolframRvnwlf tested the Qwen3-30B-A3B Unsloth quantized build on an M4 MacBook Pro:
"The 30B-A3B Unsloth quant delivered 82.20% while running locally at ~45 tok/s and with zero API spend... Quantised 30B models now get you ~98% of frontier-class accuracy - at a fraction of the latency, cost, and energy."
vLLM and SGLang are the recommended self-hosting frameworks; the Qwen3 docs include full deployment commands. For teams that process sensitive data or operate in jurisdictions where China-origin cloud compliance matters, self-hosting also resolves the data residency question entirely.
The tradeoff: hardware cost is real. A single H20 GPU node runs ~$3–5/hour on cloud providers. For moderate workloads (under a few million tokens/day), the API is likely cheaper than dedicated compute. But at scale - or with a GPU you already own - self-hosting often wins.
Qwen vs Claude vs GPT: the honest comparison
The "Qwen is 9x cheaper than Claude" framing is real but incomplete.
"The API pricing comparison tells the story clearly. Claude Opus 4.6 runs $5 input and $25 output per million tokens. GPT-5.3 Codex runs $1.75 and $14. Qwen 3.5 Plus runs $0.40 and $2.40. That's not a marginal difference. That's a structural shift in who can afford to build with frontier-level AI."
The nuance Artificial Analysis adds: Qwen models generate more output tokens per task than peers. Qwen3.5-27B used 98M output tokens to complete their Intelligence Index benchmark - meaningfully higher than MiniMax-M2.5 (56M) or DeepSeek V3.2 (61M). If your workload generates long outputs, the token verbosity partially offsets the per-token discount.
Rishabh Choudhary's LinkedIn analysis of Qwen3.6-Plus frames the core question:
"It scored 78.8 on SWE-bench Verified... Claude Opus 4.5 scored 80.9. That's a 2-point gap. The price gap? Not 2 points. More like 17x... The question isn't whether Chinese models are catching up. They clearly are. The question is whether the remaining quality gaps matter enough to justify paying 17x more. For a lot of use cases, I think the honest answer is becoming no."
The caveats from practitioners who've run Qwen in production are also worth taking seriously. From that same LinkedIn post's comments: an 11-second first-token latency on the free preview tier (a problem for multi-step agent loops where wait time compounds), and a reported 26% code-reasoning hallucination rate in production testing that "requires a verification layer that adds back some of the cost savings you're capturing on tokens."
For a straight comparison with the most popular alternatives, see Claude pricing, Gemini pricing, and Mistral AI pricing.
Benchmark context
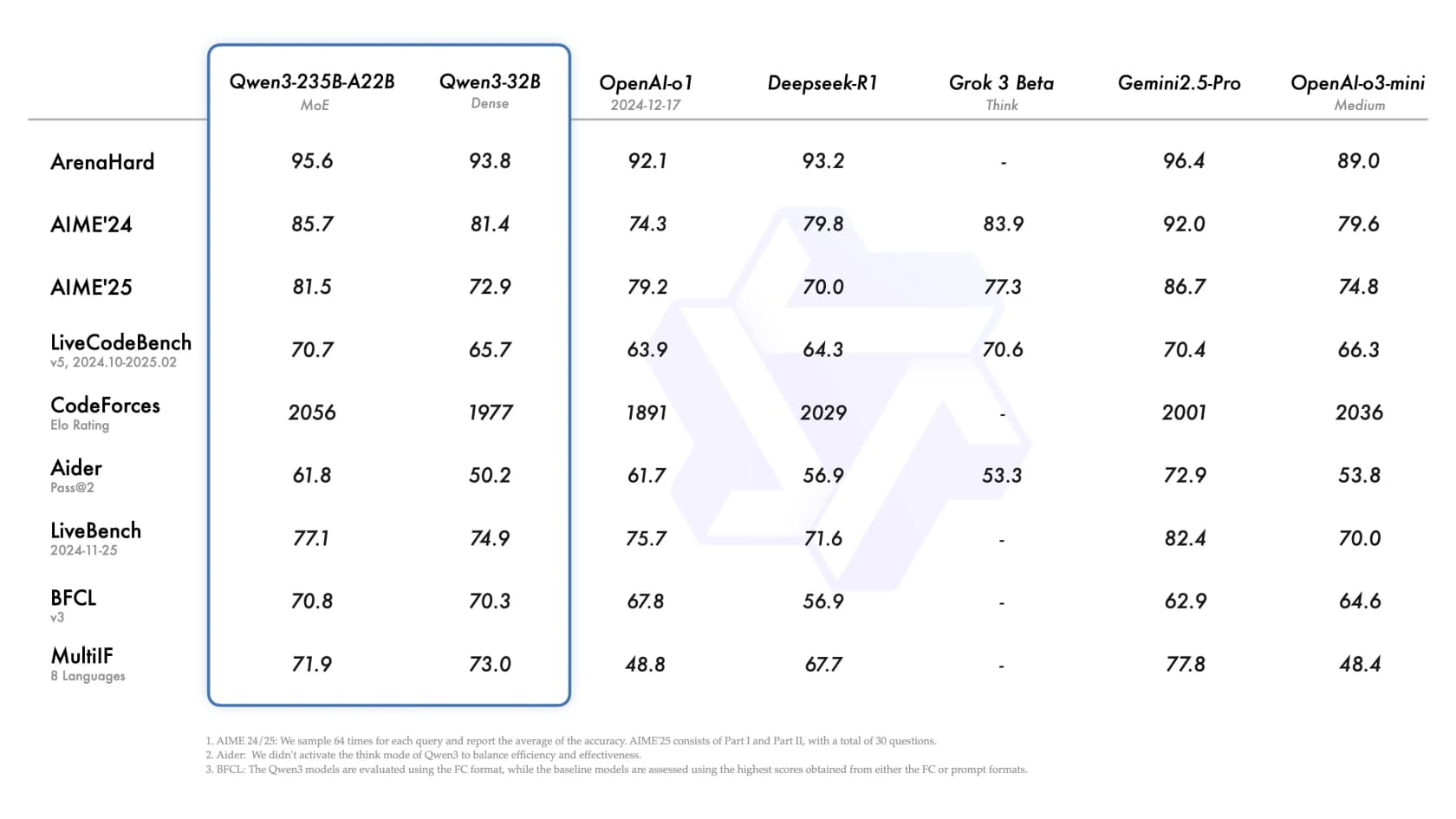
The Qwen3-235B-A22B MoE flagship competes directly with OpenAI o1, DeepSeek-R1, and Gemini 2.5 Pro on public benchmarks - ArenaHard 95.6, AIME'24 85.7, LiveCodeBench 70.7, BFCL 70.8. At $0.70/$2.80 per 1M tokens (standard), it undercuts most of those models on price while matching on score. The open-weight availability means you can also download and run it yourself without any API dependency.
The open-source download signal is telling: Qwen holds 7 of the top 10 slots in open-model Hugging Face download rankings, per Nathan Lambert (ML researcher), with Qwen2.5-7B-Instruct at 52.4M downloads and multiple Qwen3 variants in the top five. That level of adoption creates community tooling, quantized builds, and ecosystem integrations that make self-hosting increasingly accessible.
API access: how to get started
The international API runs on Alibaba Cloud Model Studio. It's OpenAI-compatible, which means swapping from OpenAI's SDK to Qwen is usually a two-line change - base URL and API key.
from openai import OpenAI
client = OpenAI(
base_url="https://[workspace-id].ap-southeast-1.maas.aliyuncs.com/compatible-mode/v1",
api_key="your-dashscope-api-key"
)
Available regions: Southeast Asia (primary), Frankfurt (since 2026-03-20), and Hong Kong (since 2026-03-17). The US Virginia endpoint is available but carries no free trial quota.
Rate limits are 600 RPM / 1M TPM for most models; Qwen-Turbo runs higher at 5M TPM, making it the right choice for bursty high-volume pipelines. Enterprise accounts can request quota increases via support ticket.
Who's actually adopting Qwen, and who's waiting
Developer adoption is strong - the Hugging Face download dominance and OpenRouter token volume make that undeniable. NVIDIA officially endorsed Qwen 3.5 on launch day, pointing developers to the NeMo build path.
Enterprise adoption is a different story. As one LinkedIn commenter noted:
"For our Fortune 500 / enterprise customers the most used models are: 1. Gemma 2. Mistral 3. GPT-OSS 4. Llama... Some of our forward thinking enterprise customers are starting to use Qwen, but it's not the majority yet."
Andrew Jardine, enterprise AI [Source]
The named blockers: China-origin compliance reviews in regulated industries (financial services, healthcare, government), and the latency on free-tier preview endpoints. The Qwen3 series carries ISO 27001 certification on the paid API, but many enterprise security reviews require additional sign-off on data residency and model access logging before procurement can proceed. Self-hosting sidesteps most of this.
For teams outside those compliance constraints - especially startups, mid-market SaaS builders, and cost-sensitive agentic pipeline operators - the economics are hard to argue with.
Try eesel
If you're running AI-powered workflows at scale and token costs matter, eesel is worth a look. It deploys autonomous AI agents directly inside the tools your team already uses - Zendesk, Slack, Freshdesk, email, Shopify - without requiring a new interface or per-seat subscription. You pay per task ($0.40 per ticket resolved, $4.00 per blog post drafted), and agents pause automatically when you hit your spend cap. The pricing model sidesteps the token-counting overhead entirely. Start with $50 free credit, no card required.
Frequently Asked Questions
How much does Qwen cost per million tokens?
Is Qwen still free in 2026?
How does Qwen pricing compare to ChatGPT and Claude?
What is Qwen's thinking mode and how is it billed?
enable_thinking: true parameter that activates chain-of-thought reasoning. Thinking output tokens are billed at a higher rate than standard output - typically 3-10x. For example, Qwen-Plus charges $1.20/1M for standard output but $4.00/1M for thinking output. Standard input tokens are billed at the same rate regardless of whether thinking is enabled.