What Together AI actually charges you for
Most pricing posts try to fit Together AI into a Build / Scale / Enterprise tier story. The pricing page just doesn't work that way. There are no named tiers. There's no per-seat fee. There's no monthly minimum on self-serve. What there is is four parallel meters, each measuring a different unit of consumption, and any given workload can land on one, two, or all four of them depending on how you deploy.
The four pillars:
- Serverless inference - you call an OpenAI-compatible
/v1/chat/completionsendpoint, you get a response, you pay per million tokens of input and output. The same surface covers chat, vision, image, audio, video, transcription, embeddings, and moderation, each with its own per-model rate (Together AI pricing). - Dedicated inference - Together provisions a single-tenant GPU instance for you, you keep it warm 24/7, you pay per GPU-hour. The dedicated meter ignores token volume entirely; you're paying for a reserved seat, not the rides.
- GPU clusters - you rent the raw NVIDIA hardware (8 to 4,000+ GPUs, InfiniBand-connected) on-demand or reserved up to six months. This is for teams training their own models or running their own inference engines.
- Fine-tuning - training is billed per token of training data, scaled by model size and method (LoRA, full FT, DPO). Then the resulting model goes onto a dedicated endpoint, which is its own per-hour meter.
This matters because picking the right meter is where the savings live. A start-up doing 5 million tokens a day on Llama 3.3 70B has no business on a dedicated endpoint; a steady-state production workload doing 500 million tokens a day on the same model usually does. Together AI's CEO Vipul Ved Prakash frames the platform as the "AI Acceleration Cloud" sitting between the two (LinkedIn), and the pricing structure reflects that: serverless to start, dedicated when you can predict load, clusters when you're training.

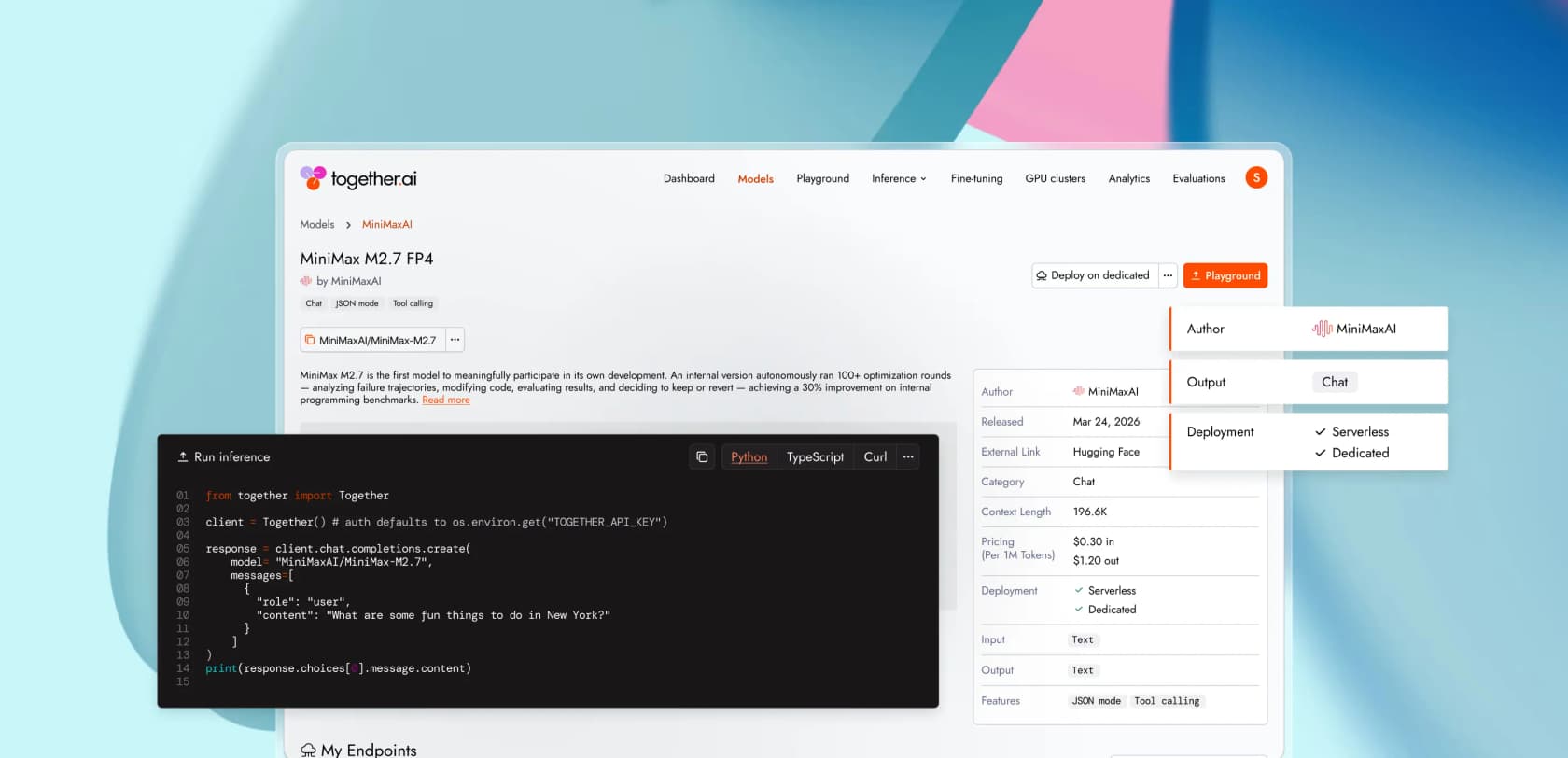
Serverless inference pricing
Serverless is the front door, and it's the meter most teams will live on. The chat-models table on together.ai/pricing lists per-million-token rates for every supported model, split into input, output, and (on some models) a cached-input rate that's significantly cheaper than the base.
A representative slice from the chat tab, lifted verbatim (Together AI pricing):
| Model | Input $/M | Output $/M | Cached input $/M |
|---|---|---|---|
| GLM-5.1 | $1.40 | $4.40 | - |
| MiniMax M2.7 | $0.30 | $1.20 | $0.06 |
| Kimi K2.6 | $1.20 | $4.50 | $0.20 |
| DeepSeek V4 Pro | $2.10 | $4.40 | $0.20 |
| DeepSeek V4 Flash | - (no price shown on page) | - | - |
| Qwen3.6-Plus | $0.50 | $3.00 | - |
| Qwen3.7-Max | $1.25 | $3.75 | $0.13 |
| gpt-oss-120B | $0.15 | $0.60 | - |
| gpt-oss-20B | $0.05 | $0.20 | - |
| Llama 3.3 70B | $1.04 | $1.04 | - |
| Qwen3 235B A22B FP8 Throughput | $0.20 | $0.60 | - |
| LFM2 24B A2B | $0.03 | $0.12 | - |
| Cogito v2.1 671B | $1.25 | $1.25 | - |
Three things worth pulling out of that table.
First, cached-input pricing is the lever nobody talks about. DeepSeek V4 Pro's input cost drops from $2.10/M to $0.20/M when the prompt prefix is cached - a 10.5× discount. Kimi K2.6 drops 6×. MiniMax M2.7 drops 5×. If your workload reuses a long system prompt or has repeated user contexts (most agent loops, most RAG pipelines), the cached rate is the real rate. The non-cached number on the table is the worst case.
Second, the model wave you're on matters more than the provider. gpt-oss-20B and LFM2 24B exist on the same pricing page as DeepSeek V4 Pro and GLM-5.1. The 100× gap between $0.03/M (LFM2 input) and $4.50/M (Kimi K2.6 output) is much bigger than the gap between Together and its competitors at the same model. "Together is cheap" is not a useful claim; "this specific model is cheap on Together" usually is.
Third, vision, image, audio, and video all carry separate per-model meters - image models price per megapixel or per image (FLUX.2 [pro] is $0.03/image; Google Imagen 4.0 Ultra is $0.06/MP), video models price per finished video (Sora 2 is $0.80, Google Veo 3.0 with audio is $3.20), and audio is split between per-minute (Whisper Large v3 at $0.0015) and per-1M-characters (Cartesia Sonic-3 at $65) (Together AI pricing). If you're building a multi-modal app, you're touching multiple meters at once and your "Together bill" is the sum, not any single rate.
The serverless front door also includes a Batch API: process up to 30 billion tokens per model asynchronously at up to 50% lower cost than synchronous serverless (Batch Inference API updates 2025). For workloads that don't need real-time latency - synthetic-data generation, offline classification, log enrichment - batch is the cheapest legitimate path on the platform.
Together pitches the serverless tier on speed as well as price. From the inference product page, the published comparisons read as "up to 2.75x faster" on Qwen3 235B 2507, "over 65% faster" on Kimi K2 0905, and "2x faster" on gpt-oss-20B versus the next-fastest provider on each benchmark. Higher tokens-per-second-per-GPU is, ultimately, what lets Together charge less and still hit margin - it's the same hardware, just doing more work per second.
Our researchers and engineers are committed to accelerating AI inference to be as fast as the laws of physics will allow.
Ce Zhang, CTO, via Ryan Pollock on LinkedIn
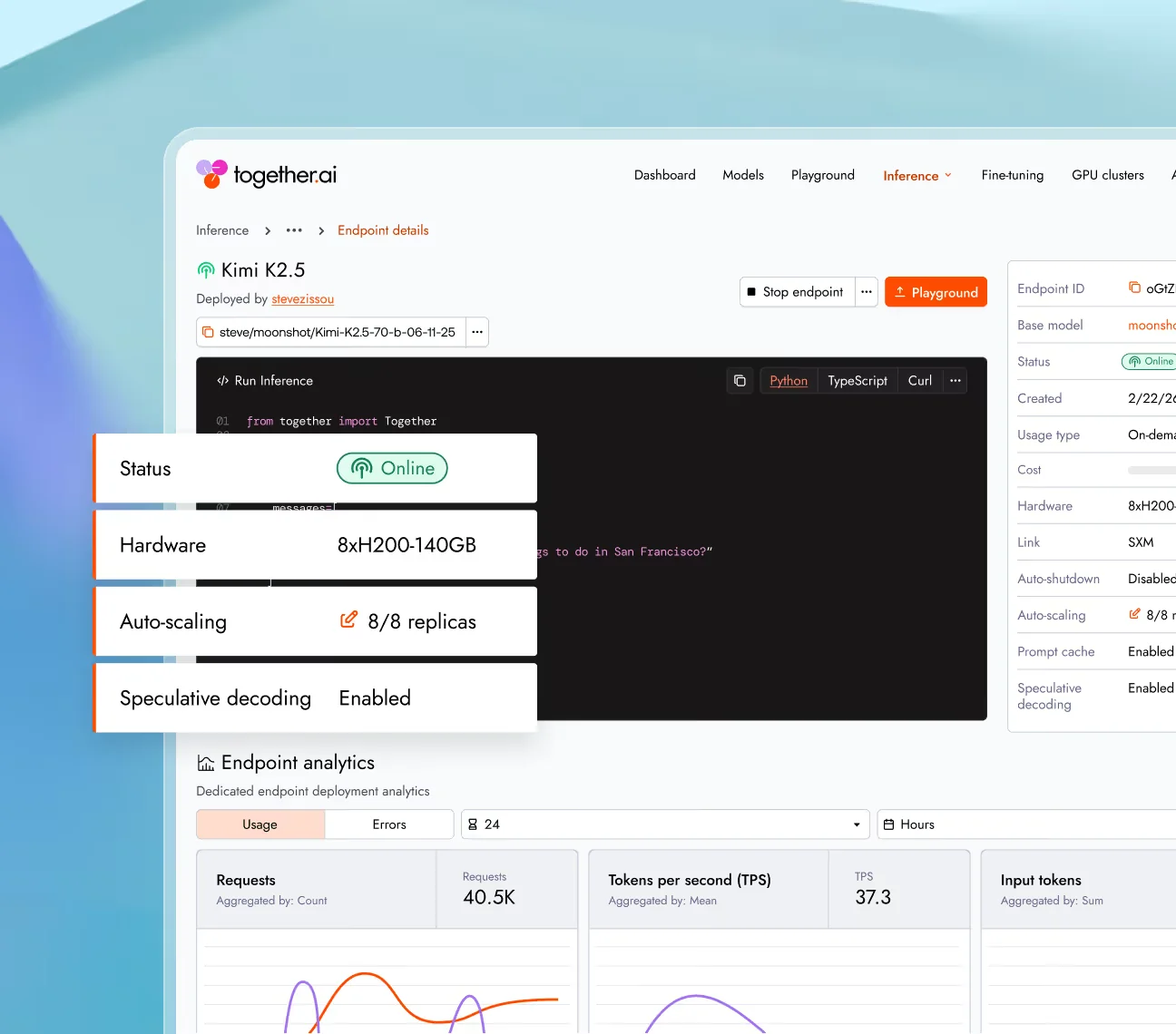
Dedicated inference pricing
Once your workload outgrows shared serverless - or, more often, once unpredictable latency from shared infrastructure becomes a product problem - Together AI's dedicated endpoints let you provision a single-tenant GPU instance and pay by the hour (Together AI pricing):
| Hardware | Price per hour |
|---|---|
| 1× H100 80 GB | $6.49 |
| 1× H200 140 GB | Contact us |
| 1× HGX B200 180 GB | $11.95 |
The math is brutal in one direction. An H100 left running 24 hours a day, 30 days a month, costs $4,672.80/month per GPU. A B200 over the same window is $8,604. Token volume is irrelevant - even at zero requests, the meter ticks.
It's also brutal in the other direction, in a good way. At high enough request volume, the per-token effective cost on a dedicated endpoint collapses below the serverless rate. The break-even depends on the model, but as a rough rule of thumb for a 70B-class model on serverless at $1.04/M tokens both ways, you start saving on dedicated somewhere north of ~5 billion tokens/month of steady, predictable traffic. Below that, serverless almost always wins on cost; above that, dedicated wins and you also pick up consistent latency.
Salesforce's research team is one of the published reference points for this tier:
We've been thoroughly impressed with Together. They delivered a 2x reduction in latency and cut our costs by approximately a third.
Caiming Xiong, VP, Salesforce AI Research, Together AI inference page
If you're considering dedicated, the question you actually need to answer isn't "is Together's $6.49/hr H100 cheaper than X?" - it's "do I have a steady-enough workload that paying for a GPU around the clock is cheaper than paying for tokens that mostly happen during business hours?" For a lot of teams the honest answer is no.
GPU cluster pricing - on-demand vs reserved
Beneath dedicated endpoints sits the rawest tier of the stack: rented GPU clusters that you operate yourself (gpu-clusters). This is where teams training their own models, running custom inference engines, or scaling beyond what dedicated endpoints offer end up.
On-demand cluster pricing (self-serve, pay-as-you-go, terminate anytime, up to 256 GPUs) (Together AI pricing):
| Hardware | Price per GPU per hour |
|---|---|
| NVIDIA HGX H100 | $5.49 |
| NVIDIA HGX H200 | $6.79 |
| NVIDIA HGX B200 | $9.95 |
Reserved cluster pricing scales down with duration, with a maximum published commitment of 180 days; anything beyond that routes to a GPU cluster request form for custom enterprise pricing (Together AI pricing):
| Hardware | 7-30 days | 31-90 days | 91-180 days | 181+ days |
|---|---|---|---|---|
| NVIDIA HGX H100 | $4.99 | $4.49 | $3.99 | Contact us |
| NVIDIA HGX H200 | $5.95 | $4.99 | $4.55 | Contact us |
| NVIDIA HGX B200 | $9.65 | $9.35 | $9.09 | Contact us |
| NVIDIA GB200 NVL72 | Contact us | Contact us | Contact us | Contact us |
| NVIDIA GB300 NVL72 | Contact us | Contact us | Contact us | Contact us |
Three things make the cluster tier interesting compared to a hyperscaler GPU rental.
First, bare-metal performance with InfiniBand interconnect throughout. Together's pitch is that "our InfiniBand interconnect keeps gradient synchronization fast and communication overhead low - so your training runs finish faster, not just bigger" (Together AI gpu-clusters). That matters because a 30% faster training run on the same hardware is, in effect, a 30% discount on the same hourly rate.
Second, the Together Kernel Collection ships with the cluster. TKC (built by Chief Scientist Tri Dao, creator of FlashAttention) is the same optimization layer that powers Together's serverless inference, and it's available on clusters too. The published benchmark: "Training a 70B parameter Llama-architecture model (BF16) with an optimized TorchTitan + Together Kernel Collection (TKC) reached 15,264 tokens/second/GPU on NVIDIA HGX B200, up from 8,080 tokens/second on NVIDIA HGX H100 - a 90% jump in training speed" (Together AI gpu-clusters).
Third, storage isn't an afterthought. Clusters come with Weka or VAST parallel filesystems attached at $0.16/GiB/month with zero egress fees (Together AI pricing). Anyone who's ever rage-quit a hyperscaler over S3 egress charges will recognize why that matters.
Together AI provides the performance and reliability we need for real-time, high-quality image and video generation at scale.
Victor Perez, Co-Founder, Krea, Together AI gpu-clusters
Fine-tuning pricing - and the hosting cost nobody warns you about
Fine-tuning on Together is billed per token of training data, not per epoch and not per GPU-hour (Together AI fine-tuning docs). The math is explicit on the pricing page: "Price is based on the sum of tokens processed in the fine-tuning training dataset (training dataset size × number of epochs) plus any tokens in the optional evaluation dataset (validation dataset size × number of evaluations)" (Together AI pricing).
The standard pricing table scales by base-model size and tuning method (Together AI pricing):
| Base model size | SFT - LoRA | SFT - Full | DPO - LoRA | DPO - Full |
|---|---|---|---|---|
| Up to 16B | $0.48 / M | $0.54 / M | $1.20 / M | $1.35 / M |
| 17B–69B | $1.50 / M | $1.65 / M | $3.75 / M | $4.12 / M |
| 70B–100B | $2.90 / M | $3.20 / M | $7.25 / M | $8.00 / M |
Beyond 100B parameters, Together prices fine-tuning per model in a "specialized" tier, often with a minimum charge per job (Together AI pricing):
| Model | SFT (LoRA) | DPO (LoRA) | Minimum |
|---|---|---|---|
| DeepSeek-R1 / V3 / V3.1 family | $10.00 / M | $25.00 / M | $20.00 |
| GLM-4.6 / 4.7 | $9.00 / M | $22.50 / M | $27.00 |
| GLM-5 / GLM-5.1 | $40.00 / M | $100.00 / M | $60.00 |
| gpt-oss-120B | $5.00 / M | $12.50 / M | $6.00 |
| Kimi K2 (Thinking / Instruct / Base) | $15.00 / M | $37.50 / M | $60.00 |
| Llama 4 Maverick / Maverick Instruct | $8.00 / M | $20.00 / M | $16.00 |
| Llama 4 Scout | $3.00 / M | $7.50 / M | $6.00 |
| Qwen3-Coder-480B-A35B-Instruct | $9.00 / M | $22.50 / M | $18.00 |
| Qwen3-235B-A22B / Instruct-2507 | $6.00 / M | $15.00 / M | No min. |
| Qwen3.5-122B-A10B | $6.00 / M | $15.00 / M | $10.00 |
| Qwen3.5-397B-A17B | $8.00 / M | $20.00 / M | $22.00 |
The table above is the one most people quote. The number they forget is that once you've trained the model, hosting it is a separate, ongoing charge.
From the docs: "Once training finishes, inference runs on a dedicated endpoint" (Together AI docs). That dedicated endpoint is metered at the same rates as the dedicated inference tier - $6.49/hr for an H100 or $11.95/hr for a B200 (Together AI pricing). A LoRA on a 16B base might train for under a dollar per million training tokens, but keeping the resulting model alive on a single H100 around the clock is roughly $4,700/month per GPU, regardless of whether it serves a request that month.
This is the single biggest pricing gotcha on the platform. Teams routinely compute "fine-tuning will cost us $30 for the run" - which is correct - and then discover the hosting bill is two orders of magnitude larger. Plan the lifecycle, not just the training step.
A few other details about fine-tuning that are easy to miss:
- No advertised free tier. Every training run bills per token from the first token.
- LoRA is the default, full fine-tuning is opt-in. The pricing-page deltas between LoRA and Full are small (about $0.30/M on the 70B tier), so the choice is usually about quality, not cost.
- DPO costs roughly 2.5× SFT across every size tier. If you're aligning a model to preferences, budget accordingly.
- BYOM (bring your own model) lets you upload a base outside the catalog. Pricing for BYOM training falls under whichever standard size bucket the model fits into; hosting is the same dedicated rates.
Sandbox, code interpreter, and managed storage
Two smaller meters are worth noting because they catch a lot of agent-builders by surprise.
Code Sandbox lets you spin up isolated VM sandboxes for AI agents to execute code in. It's priced per virtual CPU and per GiB of memory, by the hour (Together AI pricing):
| Resource | Price per hour |
|---|---|
| Per vCPU | $0.0446 |
| Per GiB RAM | $0.0149 |
A modest 4-vCPU, 8 GiB sandbox kept warm for a workday (8 hours) runs about $2.39 - small change individually, but for an agent fleet that's spinning up dozens of these in parallel, the totals can compound quickly.
Code Interpreter is the lighter cousin: a single-session sandbox for executing LLM-generated code with no warm-pool overhead, priced at $0.03 per 60-minute session (Together AI pricing). That's the sane default for most agent tool-use flows.
Managed Storage is the parallel filesystem that sits next to clusters. It's $0.16 per GiB per month with zero egress fees (Together AI pricing). A 10 TB working set costs about $1,638/month - comparable to a hyperscaler high-performance file system, but without the bandwidth bill on the way out.
What is, and isn't, free
This part is short, because there isn't much.
- No advertised free tier on the public pricing page. The page doesn't surface a signup-credit dollar amount, a free-trial period, or a monthly free-task allowance.
- The Batch API is the only inline discount mechanism: up to 50% off most chat models for asynchronous workloads (Batch Inference API updates 2025).
- Volume / committed-use discounts exist but aren't published - the page routes you to Contact us for enterprise pricing.
- Cached input is the closest thing to a free lunch: 5-10× discount on input tokens for select chat models when prefixes are reused.
Practitioners have historically referenced a starter credit:
$25 free credit goes a long way when even the most expensive models are $0.9/million tokens.
Chris Samiullah, ML engineer, LinkedIn
That number isn't currently published on the pricing page as a flat policy. If you're planning a budget, treat the credit as "ask your account manager" rather than "guaranteed."
How Together AI pricing stacks up against Fireworks, Groq, Replicate, and the rest
The honest answer is that "is Together the cheapest?" depends entirely on the model you're running, the throughput you need, and whether you're on serverless or dedicated. Here's a side-by-side for the most common shared models, with rates pulled from each provider's live pricing page on 2026-06-05:
| Provider | Llama 3.3 70B in / out $/M | DeepSeek R1 in / out $/M | Mixtral 8x22B in / out $/M | Free credits | Pricing model |
|---|---|---|---|---|---|
| Together AI | $1.04 / $1.04 | DeepSeek V4 Pro: $2.10 / $4.40 (cached $0.20 input) | Not on current lineup | None advertised; Batch 50% off | Per-token serverless, per-GPU-hour dedicated |
| Fireworks AI | $0.90 / $0.90 (>16B bucket) | DeepSeek V4 Pro: $1.74 / $3.48 | $1.20 / $1.20 (MoE 56-176B) | $1 free credit | Per-token serverless, per-GPU-second on-demand |
| Groq | $0.59 / $0.79 | Not on lineup | Not on lineup | Free console signup | Per-token serverless |
| Replicate | Per-hardware seconds | $3.75 / $10.00 | Per-hardware seconds | None advertised | Per-hardware-second + per-token for select first-party |
| Anyscale | Bring-your-own-deployment on H100 at $9.29/hr | Same | Same | $100 credit | Per-GPU-hour (Anyscale Compute Units) |
| Modal | Self-deploy on H100 ~$3.95/hr equiv | Same | Same | $30/mo Starter, $100/mo Team | Per-second compute |
| Hugging Face | Pass-through Inference Providers | Pass-through | Pass-through | PRO $9/mo + free ZeroGPU | Per-hour Endpoints + pass-through tokens |
| OpenRouter | $0.10 / $0.32 | $0.50 / $2.15 (R1 0528) | $2.00 / $6.00 | Free rate-limited variants | Per-token marketplace |
A few patterns fall out of that table.
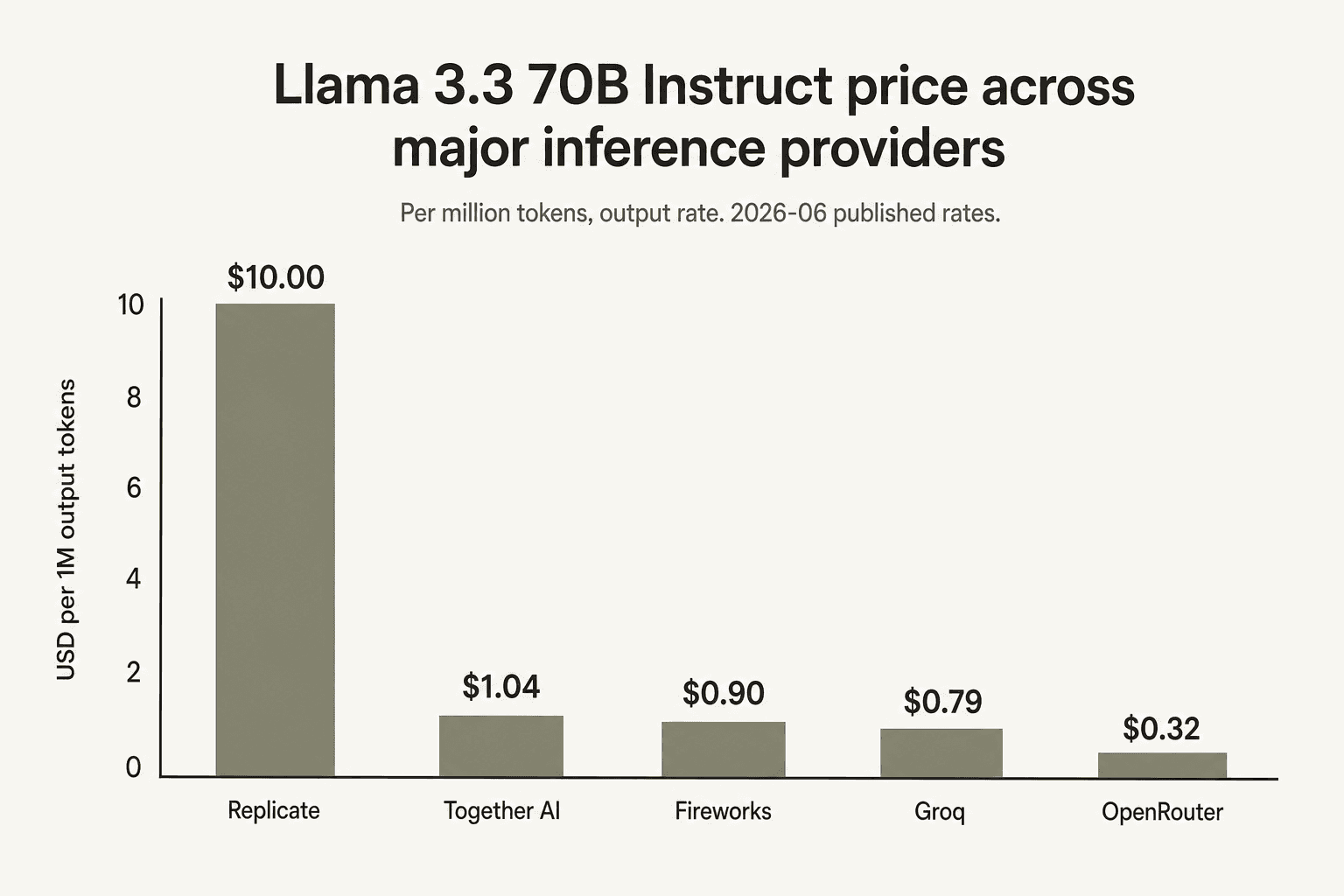
On Llama 3.3 70B specifically, Together AI is mid-pack. Groq is the cheapest first-party provider on the popular legacy model ($0.59/$0.79), Fireworks is next ($0.90 flat), Together is third ($1.04/$1.04), Replicate doesn't list it per-token at all, and OpenRouter - which is a marketplace that routes to the cheapest underlying provider - undercuts everyone at $0.10/$0.32. If your workload is "lots of Llama 3.3 70B inference," Groq and the OpenRouter marketplace deserve a serious look.
On the new-wave models - Kimi K2.6, GLM-5.1, DeepSeek V4, Qwen3.6-Plus - Together is competitive but not always cheapest. Fireworks tends to list its newer Kimi and DeepSeek individually with cached-input rates that match or beat Together's. The difference is usually within 10-30%, not the 5-10× gap you sometimes see thrown around in marketing copy.
For dedicated GPU hosting, the landscape is wider. Modal undercuts almost everyone on per-second compute (H100 ≈ $3.95/hr equivalent at $0.001097/sec). Hugging Face Endpoints publishes $4.50/hr for an H100. Together is at $6.49/hr for dedicated inference, $5.49/hr for an on-demand cluster, and $3.99/hr for a 91-180-day reserved cluster. Different products, different bills - and your real cost depends on whether you can absorb the operational complexity of running your own vLLM deployment on Modal versus letting Together host a model on your behalf.
For embeddings, Together is among the cheapest at $0.02/M tokens (Multilingual e5 large instruct) (Together AI pricing). Together's corporate account has historically advertised "up to 4x lower cost than OpenAI" on embeddings (@togethercompute on X), and the current rates are in that ballpark.
For batch workloads, Together's 50% Batch API discount is the headline lever. Fireworks matches the 50% discount; Groq does too. Replicate, Modal, and Anyscale don't have a comparable async-discount tier.
For deeper per-provider walkthroughs, our breakdowns of Fireworks AI pricing, Baseten pricing, and SambaNova Cloud pricing sit next to this one. The short version: pick the cheapest provider for the specific model you're shipping, not the cheapest provider in the abstract.
Three worked examples of what real teams actually pay
Token math is cheap; the bill at the end of the month is what matters. Here are three scenarios with the actual numbers.
Example 1 - A SaaS team running an in-product chat assistant on Llama 3.3 70B
Traffic: 5,000 conversations/day, averaging 1,500 input tokens (system prompt + retrieved context) and 400 output tokens per conversation. About 21 working days a month.
Serverless math at Together's $1.04/M input + $1.04/M output:
- Input: 5,000 × 1,500 × 21 = 157.5M tokens × $1.04 = $163.80/mo
- Output: 5,000 × 400 × 21 = 42M tokens × $1.04 = $43.68/mo
- Total: ~$207/mo on the inference line
If the same team picks Groq instead at $0.59 input / $0.79 output:
- 157.5M × $0.59 + 42M × $0.79 = $92.92 + $33.18 = ~$126/mo
If they go OpenRouter at $0.10 input / $0.32 output:
- 157.5M × $0.10 + 42M × $0.32 = $15.75 + $13.44 = ~$29/mo
Headline: at this volume, the pure inference cost is small enough that the choice probably comes down to latency, regional reliability, support responsiveness - not the inference rate.
Example 2 - An AI-native start-up running a Kimi K2.6 agent loop at scale
Traffic: 200M input tokens/day, 50M output tokens/day, with about 80% of input cacheable (long system prompt + reused tool definitions). 30 days a month.
Together math with cached pricing baked in:
- Input (cached): 200M × 0.80 × 30 × $0.20/M = $960/mo
- Input (uncached): 200M × 0.20 × 30 × $1.20/M = $1,440/mo
- Output: 50M × 30 × $4.50/M = $6,750/mo
- Total: ~$9,150/mo
Without the cached-input discount, the input portion alone would be $7,200, so the cached lever is worth roughly $5,800/mo in this scenario. Most teams underestimate how big the cached-input discount is, because most pricing comparisons quote the uncached rate.
Example 3 - A team fine-tuning Llama 4 Scout and hosting it 24/7
Training: 500M tokens of training data on Llama 4 Scout. From the specialized tier, that's $3.00/M LoRA SFT with a $6 minimum.
- Training cost: 500 × $3.00 = $1,500 one-off
Hosting: 1× H100 dedicated endpoint kept warm for production.
- $6.49/hr × 24 hr × 30 days = $4,672.80/mo, every month
Total first-month bill: $1,500 + $4,672.80 ≈ $6,173. Steady-state from month two onward: $4,673.
The training cost looks like the headline. The hosting cost is the actual recurring bill. If you can host the fine-tuned model on existing dedicated capacity, or if your traffic justifies serverless on the base model + targeted prompt engineering instead of a full fine-tune, you can erase the $4,673 line entirely. Plan the lifecycle.

Where Together's pricing has caught teams off guard
The most consistent thread across the negative reviews on G2 and Trustpilot isn't about the headline rates - it's about billing mechanics. Three specific complaints come up repeatedly.
Unrefunded authorization charges. Several Trustpilot reviewers describe adding a credit card, getting hit with a $1 authorization that's supposed to reverse, and then not getting the dollar back:
When you add a credit card it explicitly said: "There will be an immediate $1 charge for authorization, which will be credited back." I added my credit card, got charged $1, but never received it back.
Trustpilot reviewer, Together AI on Trustpilot
Rapid-interval charges and weak refund follow-through. Another billing-pattern thread:
They were charging the credit card in second intervals with weird amounts - had to emergency block the card. Support not reachable.
Trustpilot reviewer, Together AI on Trustpilot
After 2 weeks they still have not refunded the remaining balance on my prepaid account, nor would they refund the amount for troubleshooting the deactivated API key.
G2 reviewer, Together AI on G2
These aren't typical of the median customer experience - most G2 reviewers are positive - but they're consistent enough that the negative cluster is unmistakably about billing and support response, not feature gaps. If you're a small team without an account manager, set up a separate corporate card with a tight limit, and don't pre-load large credit balances.
Fine-tune hosting surprise. Covered above, but worth restating: the cost of keeping a fine-tuned model alive is often 50× to 200× the cost of training it for any reasonable monthly volume. This catches a lot of teams. The dedicated endpoint meter doesn't pause when the model is idle.
Engineering time is the biggest invisible cost. Pulled from a recurring practitioner critique surfaced across LinkedIn and X threads about Together AI pricing:
Using Together AI isn't exactly a plug-and-play experience. It takes a good amount of developer time to integrate its API, build an application around it, and then maintain that system over time. These engineering costs can add up fast and often end up being much higher than the API usage itself.
Recurring practitioner critique surfaced via LinkedIn / X discussions about Together AI pricing
This isn't a knock on Together specifically; it applies to every raw-API inference platform. If your engineering team's time isn't free, the spreadsheet that compares Together's $1.04/M Llama 3.3 70B against Groq's $0.59/M Llama 3.3 70B should also include the engineer-weeks needed to handle authentication, retry/backoff, observability, structured-output validation, prompt versioning, eval pipelines, and on-call rotation. For many teams those engineering line items dwarf the inference line item entirely.
When Together AI is the right call - and when it isn't
Where Together pricing actively shines:
- You're running fine-tuned open-source models at predictable, steady-state production traffic. Dedicated endpoints at $6.49/hr or reserved clusters at $3.99/hr per H100 are competitive with hyperscaler GPU rentals and a fraction of the price of frontier proprietary APIs at equivalent quality bands.
- You need GPU clusters with InfiniBand without rolling your own data center. Together's 8-to-4,000+ GPU range and 25+ city footprint, plus the Together Kernel Collection performance edge, are genuinely competitive with anything outside the largest hyperscalers (gpu-clusters).
- You're building multi-modal experiences and want one API. The serverless tier covers chat, vision, image, audio, video, transcription, embeddings, and moderation, so you're not stitching together six separate provider accounts.
- You're running large async / batch workloads. The 50% Batch API discount on top of already-competitive serverless rates is hard to beat for offline summarization, synthetic-data generation, log enrichment, and classification at scale.
Where Together pricing is the wrong tool:
- You just need the cheapest Llama 3.3 70B endpoint money can buy. Groq is faster and cheaper on that specific model. OpenRouter is cheaper still. Together is mid-pack on legacy models.
- You're a small team that wants a managed AI agent for one specific surface - support tickets, sales chat, internal help - and you don't want to assemble inference + retrieval + tool-use + UI + eval yourself. This is where a per-outcome platform makes more sense; more on that next.
- You want predictable, capped pricing. Pay-as-you-go on multiple meters is hard to forecast in advance. Without a spend cap, a runaway agent loop can cost real money before anyone notices.
- You need a published SLA on first-party support response time. Multiple negative reviews flag support responsiveness around billing disputes, which is something to negotiate up front in an enterprise contract.
For deeper alternative breakdowns, see our Together AI alternatives roundup, the Together AI review, and the broader what is Together AI guide.
Try eesel when you'd rather buy outcomes than tokens
A pricing post on Together AI is almost always a pricing post on the raw materials of an AI product - tokens, GPU-hours, inference latency, fine-tune training tokens. Those are the right primitives if you're building a foundation-model company or a custom inference engine. They're the wrong primitives if what you actually want is a working AI agent inside your existing tools.
eesel takes the opposite shape: per-task pricing for a fully-managed AI teammate that runs inside the helpdesks, chat apps, and inboxes you already use (Zendesk, Freshdesk, Intercom integration, Slack, Gmail, Shopify, and 100+ others). A support ticket is $0.40. A dashboard question is free. A long-form blog generation is $4. The inference, retrieval, prompt iteration, retries, eval, and observability are all inside that number - you don't see them on the bill and you don't have to build them yourself.
Hire AI teammates. Fully autonomous and incredibly capable teammates, living in your existing apps and ready to go in minutes.
A worked comparison for the Example 1 SaaS team above - 5,000 conversations/day, in-product chat assistant. On Together, the inference line is roughly $207/mo plus the engineering time to assemble retrieval, retry logic, output validation, prompt versioning, and analytics. On eesel, that same 5,000 conversations × 21 days = 105,000 tasks/mo at $0.40 each = $42,000/mo for the same outcome - much more expensive on paper, but it includes a working product end-to-end and an SLA on resolutions. The right answer depends on whether your team's time is better spent building infrastructure or building product.
For most teams where AI support, AI chat, or AI content is the output rather than the core technology, the per-task model wins. eesel's $50-credit free trial lets you try a real workload - a helpdesk agent, a blog writer, an e-commerce agent - with no card required, and the annual commit discount is 25% if you're past $300/mo of spend. No per-seat fee, no platform fee on self-serve, no monthly minimum.
If you're already on Together AI and happy with what it gives you, you should stay there. If you're on Together AI because you couldn't find a higher-level alternative - that's exactly the gap eesel was built for.
Frequently Asked Questions
How much does Together AI cost to use in 2026?
Does Together AI have a free tier or starter credit?
How does Together AI fine-tuning pricing work?
Is Together AI cheaper than Fireworks AI, Groq, or Replicate?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.